merge sort와 같이 running time이 O(nlgn)이다.
insertion sort와 같이 sorts in place이다.
Heaps
complete binary tree이다. 높이가 k일 때 k-1까지는 노드가 모두 채워져 있고 마지막 레벨 k부터는 왼쪽부터 오른쪽으로 노드가 채워지는 tree.
참고) full binary tree : 각 레벨에 노드가 꽉 차있는 트리
힙의 종류
힙은 배열에 저장할 수 있다.
배열 A[1]에 루트노드가 저장되고 A[2]부터 레벨순으로 왼쪽에서 오른쪽으로 차례대로 배열에 저장된다.
배열에서 노드의 부모값과 자식값을 알 수 있는 방법
Parent(i) = floor(i/2)
left(i) = 2i
right(i) = 2i+1
heap의 높이
각 레벨의 노드 갯수 ; 1, 2, 4, 8 ..... 2^(n-1)
k레벨일 때까지 등비수열 합을 해주면 총 노드 갯수 n = 2^k -1
k = lg(n+1) 따라서 높이 h = θ(lgn)
Maintaining the heap property
max힙에서 n번 최대값을 뽑는 비용은? (Heap sort)
O(nlgn)
루트가 최대값이므로 그 값을 뽑고 루트 자리에 가장 낮은 노드를 넣어서 max heapify 한다. 그래서 n-1번 동안 O(lgn) 이므로 O(nlgn)
Priority queue
우선순위 개념을 큐에 도입한 자료 구조. 데이터가 우선순위를 가지고 있고 우선 순위가 높은 데이터가 먼저 나가게 된다. 힙으로 구현할 수 있다.
최대값을 읽는 것은 O(1)이고 읽고 지우는 것은 지우고 나서 Max heapify가 사용되므로 O(lg n)
노드의 키값을 증가시킬때, 바꾼 값이 힙을 깨뜨릴 가능성이 있다. 힙을 유지하기 위해 위로 올라가면서 자기자리를 찾는다. 기껏 올라가봤자 트리 높이 보다 작다. O(lg n)
노드를 삽입할 때는 힙의 맨 마지막에 넣고 힙을 유지하기 위해 노드를 위로 올리면서 자기자리를 찾는다. 이것도 O(lg n)
insertion sort와 같이 sorts in place이다.
Heaps
complete binary tree이다. 높이가 k일 때 k-1까지는 노드가 모두 채워져 있고 마지막 레벨 k부터는 왼쪽부터 오른쪽으로 노드가 채워지는 tree.
참고) full binary tree : 각 레벨에 노드가 꽉 차있는 트리
힙의 종류
max-heaps 과 min-heaps가 있다.
max-heap
부모 노드 값이 항상 같거나 크다. A[Parent(i)] >= A[i]
루트 노드는 최대값이다.
subtree의 루트노드는 그 subtree의 최대값이다.
min-heap
부모노드값이 항상 작거나 같다.
루트노드는 최소값이다.
max-heap
부모 노드 값이 항상 같거나 크다. A[Parent(i)] >= A[i]
루트 노드는 최대값이다.
subtree의 루트노드는 그 subtree의 최대값이다.
min-heap
부모노드값이 항상 작거나 같다.
루트노드는 최소값이다.
힙은 배열에 저장할 수 있다.
배열 A[1]에 루트노드가 저장되고 A[2]부터 레벨순으로 왼쪽에서 오른쪽으로 차례대로 배열에 저장된다.
배열에서 노드의 부모값과 자식값을 알 수 있는 방법
Parent(i) = floor(i/2)
left(i) = 2i
right(i) = 2i+1
heap의 높이
각 레벨의 노드 갯수 ; 1, 2, 4, 8 ..... 2^(n-1)
k레벨일 때까지 등비수열 합을 해주면 총 노드 갯수 n = 2^k -1
k = lg(n+1) 따라서 높이 h = θ(lgn)
Maintaining the heap property
Max-Heapify
노드의 왼쪽 오른쪽 서브트리가 max heap인데 정작 노드는 자식노드보다 작을 때 부모는 자식보다 크다는 max heap 속성을 어기므로 만족할때까지 밑으로 내린다. 내려가는 횟수는 아무리 많아도 트리의 높이보다 작다. O(h) = O(lg n)
Building a heap
자식을 가진 맨 아래 오른쪽에 있는 노드부터 시작해서 Max-heapify 해준다. (밑에서부터 힙이 이루어지도록 한다.) 다음 max-heapify 해줄 노드 방향은 오른쪽 -> 왼쪽, 아래 -> 위다.
위에서부터 밑으로 내려가는 방식은 힙이라는 것을 보증하지 못하기 때문에 힙이 안만들어 질 수도 있다.
Running time
Upper bound는 Max-HEAPIFY가 O(lg n)이므로 노드 O(n)개에 대해 수행하면 O(nlg n) 이 된다.
Thighter bound를 살펴보면 트리의 아래쪽에 있는 노드는 lg n보다 적은 시간이 들고 이러한 아래에 있는 노드들이 많으므로 tighter bound는 Upper bound 보다 작다. 계산하면 O(n)이 된다. linear time으로 기존의 배열을 힙으로 만들 수 있다.
노드의 왼쪽 오른쪽 서브트리가 max heap인데 정작 노드는 자식노드보다 작을 때 부모는 자식보다 크다는 max heap 속성을 어기므로 만족할때까지 밑으로 내린다. 내려가는 횟수는 아무리 많아도 트리의 높이보다 작다. O(h) = O(lg n)
Building a heap
자식을 가진 맨 아래 오른쪽에 있는 노드부터 시작해서 Max-heapify 해준다. (밑에서부터 힙이 이루어지도록 한다.) 다음 max-heapify 해줄 노드 방향은 오른쪽 -> 왼쪽, 아래 -> 위다.
위에서부터 밑으로 내려가는 방식은 힙이라는 것을 보증하지 못하기 때문에 힙이 안만들어 질 수도 있다.
Running time
Upper bound는 Max-HEAPIFY가 O(lg n)이므로 노드 O(n)개에 대해 수행하면 O(nlg n) 이 된다.
Thighter bound를 살펴보면 트리의 아래쪽에 있는 노드는 lg n보다 적은 시간이 들고 이러한 아래에 있는 노드들이 많으므로 tighter bound는 Upper bound 보다 작다. 계산하면 O(n)이 된다. linear time으로 기존의 배열을 힙으로 만들 수 있다.
max힙에서 n번 최대값을 뽑는 비용은? (Heap sort)
O(nlgn)
루트가 최대값이므로 그 값을 뽑고 루트 자리에 가장 낮은 노드를 넣어서 max heapify 한다. 그래서 n-1번 동안 O(lgn) 이므로 O(nlgn)
Priority queue
우선순위 개념을 큐에 도입한 자료 구조. 데이터가 우선순위를 가지고 있고 우선 순위가 높은 데이터가 먼저 나가게 된다. 힙으로 구현할 수 있다.
최대값을 읽는 것은 O(1)이고 읽고 지우는 것은 지우고 나서 Max heapify가 사용되므로 O(lg n)
노드의 키값을 증가시킬때, 바꾼 값이 힙을 깨뜨릴 가능성이 있다. 힙을 유지하기 위해 위로 올라가면서 자기자리를 찾는다. 기껏 올라가봤자 트리 높이 보다 작다. O(lg n)
노드를 삽입할 때는 힙의 맨 마지막에 넣고 힙을 유지하기 위해 노드를 위로 올리면서 자기자리를 찾는다. 이것도 O(lg n)
'공부 > 알고리즘' 카테고리의 다른 글
| 8장 Sorting in Linear Time (0) | 2011.07.03 |
|---|---|
| 7장 Quicksort (0) | 2011.07.03 |
| 4 Recursion (0) | 2011.06.28 |
| 3장 Growth of Funtions (0) | 2011.06.24 |
| 2장 insertion sort, merge sort, binary search, selection sort, bubble sort (1) | 2011.06.23 |



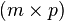 matrix
matrix  with
with 
 matrix
matrix  with
with 

 as an
as an  matrix with
matrix with 
